可以观察系统在不同压力下的行为,评估系统的容量,掌握哪些是重要的变化,或者观察系统如何处理不同的数据。
主要分为对整个系统测试以及单独测试MySQL。
EXPLAIN SELECT 1;
使用EXPLAIN可以查看某个语句具体执行计划是什么。
table
id
select_type
type
possible_keys和key
key_len
ref
rows
filtered
0.00~100.00。extra
子查询物化:将子查询的结果存储在临时表中,然后在主查询中使用该临时表的结果来执行查询。避免重复计算。
常见的性能排序:
system → const → eq_ref → ref → fulltext → range → index → all
连接池是实现连接复用的手段,和mysql交互时,每次需要建立一个连接,用完就会关掉,这就是短连接。如果在高并发场景,反复建立连接的成本是很高的,所以我们可以使用长连接,即连接用完后先不关闭,放到一个池子里等待复用,这个池子就叫连接池。
通过以下参数来控制连接池中数量:
初始连接池为空,创建一定数量的连接,完成后根据上述参数,放入连接池中,进行复用,超过最大空闲连接数就释放一部分避免浪费,不够用再建立新的连接,但是也不能太多。
CPU配置得更高。超过CPU核心数后,不同核心在不同的线程间反复切换执行,上下文切换成本较高。PostgreSQL提供的计算公式:最大连接数 = (CPU核心数 * 2) + 有效磁盘数
CPU核数放首位考虑,紧接着是磁盘,最后是网络带宽,因为带宽会影响SQL执行时间,综合考虑后才能计算出最合适的连接数大小。InnoDB引擎基本上都会将数据操作放到内存中完成,而当一张表的字段数量越多,那么能载入内存的数据页会越少,当操作时数据不在内存,又不得不去磁盘中读取数据,这显然会很大程度上影响MySQL性能。
30个字段左右,否则会导致查询时的性能明显下降。要指选择合适的数据类型,大多数开发在设计表字段结构时,如果要使用数值类型一般会选择int,使用字符串类型一般会选择varchar,但这些字段类型可以适当的做些调整。
在选择字段的数据类型时有三个原则:
CPU缓存,同时在处理速度也会更快。NULL,定义字段时应尽可能使用NOT NULL关键字,因为字段空值过多会影响索引性能。IP的存储可以使用int而并非varchar,因为简单的数据类型,操作时通常需要的CPU资源更少。like查询会导致索引失效,而采用全文索引的方式做模糊查询效率会更高更快,并且全文索引的功能更为强大。hash结构代替B+Tree结构,因为Hash结构的索引是所有数据结构中最快的,散列度足够的情况下,复杂度仅为O(1)。InnoDB将是MySQL启动后使用最多的引擎,所以为其分配一个足够大的缓冲区,能够在最大程度上提升MySQL的性能。
当InnoDB缓冲区空间大于1GB时,InnoDB会自动将缓冲区划分为多个实例空间,这样做的好处在于:多线程并发执行时,可以减少并发冲突。
调大sort_buffer、read_buffer、join_buffer几个区域,这几个部分属于每个线程私有区域。
避免创建的临时表被写入到磁盘中,违背了创建临时表加速查询的初衷。
手动调整成30min~1h左右,可以让无用的连接能及时释放,减少资源的占用。其他的通过客户端连接进行调整。
正常的项目业务中,往往读请求的数量远超写请求,如果将所有的读请求都落入数据库处理,这自然会对MySQL造成巨大的访问压力,严重的情况下甚至会由于流量过大,直接将数据库打到宕机。
因此有了Redis,架设在应用程序和数据库中间。
在缓存Key设计合理的情况下,至少能够为MySQL分担70%以上的读压力。查询MySQL之前先查询一次Redis,Redis中有缓存数据则直接返回,没有数据时再将请求交给MySQL处理,从MySQL查询到数据后,再次将数据写入Redis,后续有相同请求再来读取数据时,直接从Redis返回数据即可。
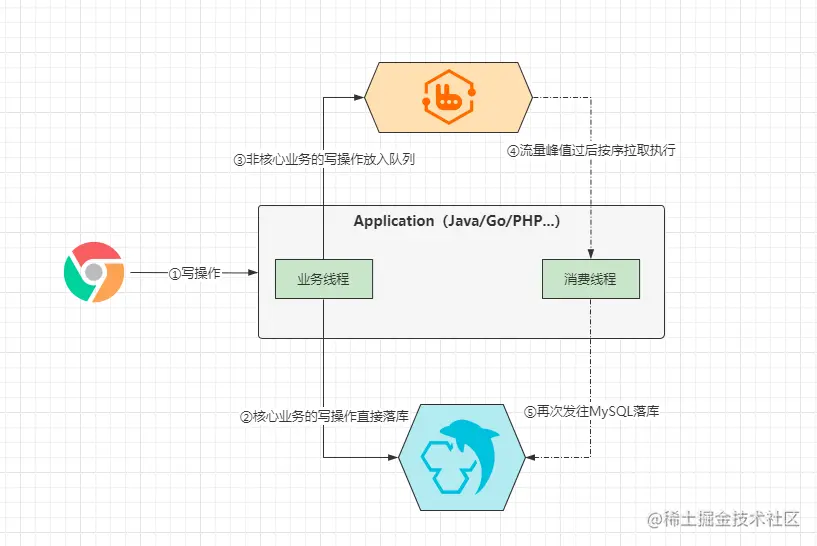
主从复制:一台为主机,另一台为从机,从节点会一直不断的从主节点上同步增量数据,当主节点发生故障时,从节点可以替换原本的主节点,以此来为客户端提供正常服务。
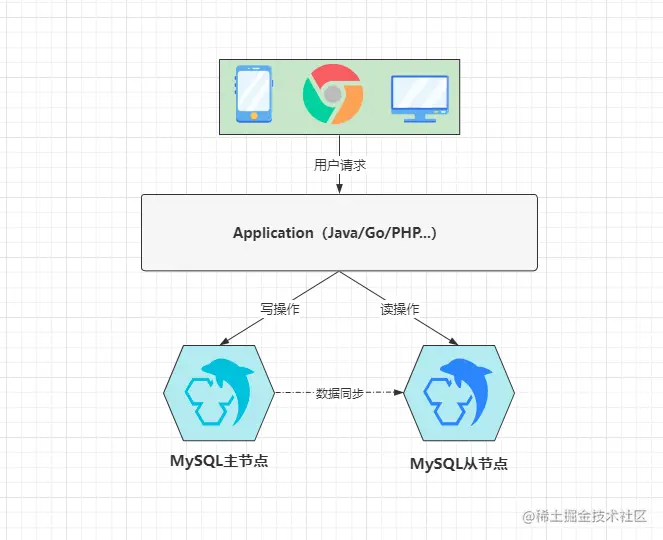
双主双写热备:两台主机可以同时读写操作,请求可以在任意一台主机上完成。两台主机之间要进行同步数据。
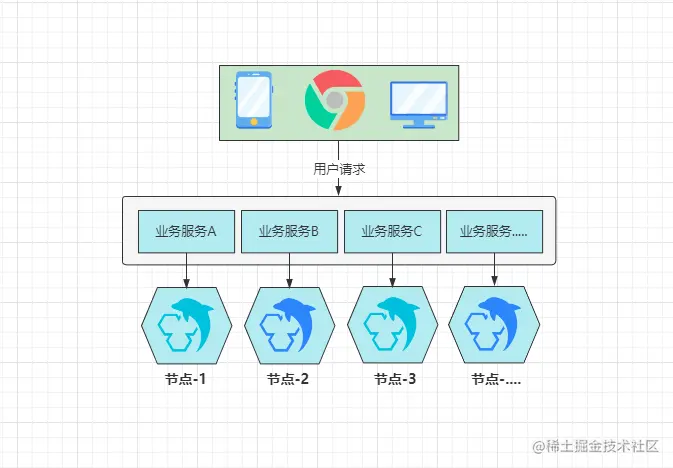
分库分表:解决了多主主机造成的存储容量的木桶问题,每个业务读写不同的数据库,不会同步。
查询时尽量不要使用*
*时,解析器需要先去解析出当前要查询的表上*表示哪些字段,因此会额外增加解析成本。*时,查询时每条数据会返回所有字段值,然后这些查询出的数据会先被放到结果集中,最终查询完成后会统一返回给客户端,分机器部署,网络数据包体积增加。连表查询时尽量不要关联太多表
多表查询时一定要以小驱大
索引失效的情况:
null的情况不会走索引必要情况下可以强制指定索引,在存在多个索引时,优化器不一定智能。
尽量将大事务拆分为小事务执行
MySQL系统。从业务设计层面减少大量数据返回的情况
尽量避免深分页的情况出现
SQL务必要写完整,不要使用缩写法
MySQL底层都需要做一次转换,将其转换为完整的写法。基于联合索引查询时请务必确保字段的顺序性
客户端的一些操作可以批量化完成
明确仅返回一条数据的语句可以使用limit 1
1s内得到响应,用户会觉得系统响应很快,体验非常好。1~3秒内得到响应,处于可以接受的阶段,其体验感还算不错。3~5秒时才可响应,这是用户就感觉比较慢了,体验有点糟糕。5秒,用户体验感特别糟糕,通常会选择离开或刷新重试。