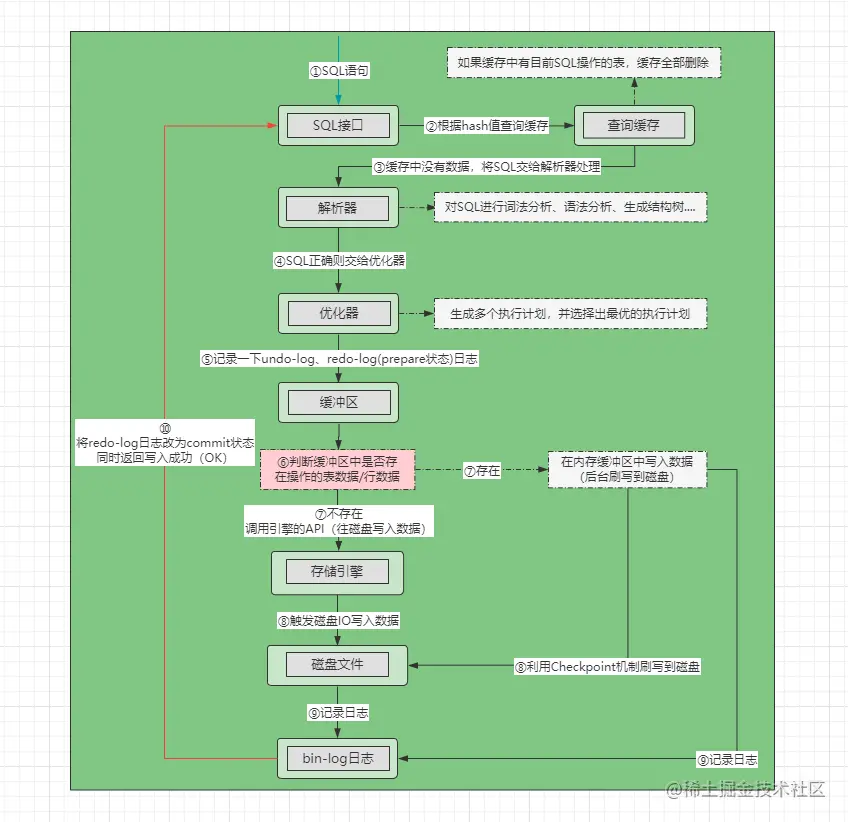
执行一条Update语句,期间会发生什么:
此外,更新的语句的流程会涉及到 undo log(回滚日志)、redo log(重做日志) 、binlog (归档日志)这三种日志:
MySQL默认开启自动提交事务,但是如果事务没有提交,MySQL发生了崩溃,需要回滚到事务之前的数据,从而保证事物的原子性。
在事务执行的过程中,MySQL会先记录更新前的数据到undo log日志文件当中,当事务回滚时,利用undo log进行回滚。
当一个事务需要回滚时,本质上并不会以执行反
SQL的模式还原数据,而是直接将roll_ptr回滚指针指向的Undo记录,从xx.ibdata共享表数据文件中拷贝到xx.ibd表数据文件,覆盖掉原本改动过的数据。
InnoDB默认是将Undo-log存储在xx.ibdata共享表数据文件当中,默认采用段的形式存储。
xx.ibdata文件中,将表中行数据的隐藏字段:roll_ptr回滚指针会指向xx.ibdata文件中的旧数据,然后再写表上的数据。Undo-log究竟在xx.ibdata文件中怎么存储呢?在共享表数据文件中,有一块区域名为Rollback Segment回滚段,每个回滚段中有1024个Undo-log Segment,每个Undo段可存储一条旧数据,而执行写SQL时,Undo-log就是写入到这些段中。如何实现MVCC的
MVCC 是通过 ReadView + undo log 实现的。undo log 为每条记录保存多份历史数据,MySQL 在执行快照读(普通 select 语句)的时候,会根据事务的 Read View 里的信息,顺着 undo log 的版本链找到满足其可见性的记录。
MySQL数据都是存储到磁盘当中,当需要更新一条记录时,从磁盘读取记录,然后在内存中修改这条记录,先缓存起来,便于后续查询直接命中,减少磁盘IO。因此有了Buffer Pool。
读取数据时,如果数据在Buffer Pool当中,客户端会直接读取Buffer Pool中的数据,否则再去磁盘中读取。
当修改数据时,如果数据存在Buffer Pool当中,直接修改Buffer Pool中数据,然后将其设置为脏页,等待后台线程选择合适的时机将脏页写入磁盘中。
Buffer Pool以页为单位进行缓存数据,一个页的默认大小为16KB。
Buffer Pool 除了缓存「索引页」和「数据页」,还包括了 Undo 页,插入缓存、自适应哈希索引、锁信息等等。
当我们查询一条记录时,InnoDB 是会把整个页的数据加载到 Buffer Pool 中,将页加载到 Buffer Pool 后,再通过页里的「页目录」去定位到某条具体的记录。
事务提交后不会立马删除Undo记录,因为可能会有其他事务在通过快照,读Undo版本链中的旧数据,直接移除可能会导致其他事务读不到数据,因此删除的工作就交给了purger线程。
Buffer Pool提高了读写效率,减少磁盘IO,但是基于内存的Buffer Pool遭遇断电重启,还没更新的脏页数据会丢失。为了防止断电导致数据丢失的问题,当一条记录更新的时候,InnoDB引擎就会先更新内存(同时标记为脏页),将本次对页的修改以redo log形式记录下来,后续先将redo log持久化。
后续,InnoDB 引擎会在适当的时候,由后台线程将缓存在 Buffer Pool 的脏页刷新到磁盘里,这就是 WAL (Write-Ahead Logging)技术。
WAL 技术指的是, MySQL 的写操作并不是立刻写到磁盘上,而是先写日志,然后在合适的时间再写到磁盘上。
在事务提交时,只要先将 redo log 持久化到磁盘即可,可以不需要等到脏页数据持久化到磁盘。当系统崩溃时,虽然脏页数据没有持久化,但是 redo log 已经持久化,接着 MySQL 重启后,可以根据 redo log 的内容,将所有数据恢复到最新的状态。
redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值;
undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值;
写入 redo log 的方式使用了追加操作, 所以磁盘操作是顺序写,而写入数据需要先找到写入位置,然后才写到磁盘,所以磁盘操作是随机写。
磁盘的「顺序写 」比「随机写」 高效的多,因此 redo log 写入磁盘的开销更小。先写入日志当中,再找合适的时间更新到磁盘上,开销更小。
此外,日志比数据先落入磁盘,就算MYSQL崩溃也可以通过日志恢复数据。
刷盘的时机由innodb_flush_log_at_trx_commit参数来控制,默认是处于第二个级别,也就是每次提交事务时都会刷盘,这也就意味着一个事务执行成功后,相应的Redo-log日志绝对会被刷写到磁盘中,因此无需担心会出现丢失风险。
redo log也有自己的buffer,先写入redo log buffer当中,后续再持久化到磁盘当中。
主要有下面几个时机:
默认情况下, InnoDB 存储引擎有 1 个重做日志文件组( redo log Group),「重做日志文件组」由有 2 个 redo log 文件组成。
MySQL通过来回写这两个文件的形式记录Redo-log日志,用两个日志文件组成一个“环形”。
redo log循环写的形式,相当于一个环形,来重复写。对于已经刷新到磁盘的脏页,擦除旧的记录,腾出空间记录新的更新操作。
MySQL 在完成一条更新操作后,Server 层还会生成一条 binlog,等之后事务提交的时候,会将该事物执行过程中产生的所有 binlog 统一写 入 binlog 文件。
binlog 文件是记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如 SELECT 和 SHOW 操作。binlog是所有引擎都能用的日志。
早期MySQL只有MyISAM,但是MyISAM不支持事务,光靠bin-log不能进行灾难恢复,binlog 日志只能用于归档。后来引入InnoDB,为了保证crash-safe能力,增加了redo log。
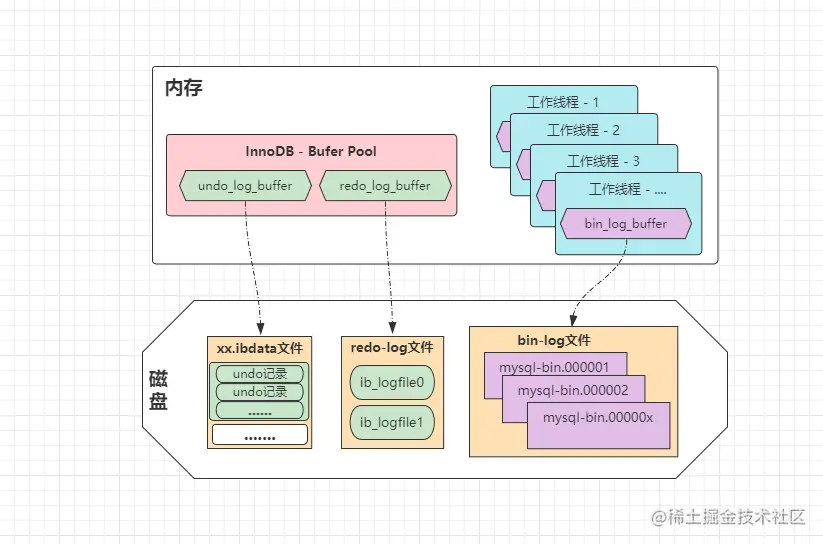
bin_log_buffer是位于每条线程中的。MySQL设计时要兼容所有引擎,直接将bin-log的缓冲区,设计在线程的工作内存中,这样就能够让所有引擎通用,并且不同线程/事务之间,由于写的都是自己工作内存中的bin-log缓冲,因此并发执行时也不会冲突①生效范围不同,Redo-log是InnoDB专享的,Bin-log是所有引擎通用的。
②写入方式不同,Redo-log是用两个文件循环写,而Bin-log是不断创建新文件追加写。
③文件格式不同,Redo-log中记录的都是变更后的数据,而Bin-log会记录变更SQL语句。
④使用场景不同,Redo-log主要实现故障情况下的数据恢复,Bin-log则用于数据灾备、同步。
如果不小心整个数据库的数据被删除了,能使用 redo log 文件恢复数据吗?
binlog记录MySQL上的所有变化并以二进制形式保存在磁盘上,复制的过程是将binlog中的数据从主库传输到从库中。
MySQL 集群的主从复制过程梳理成 3 个阶段,过程一般是异步的:
- 从库数量越多会造成IO线程数量增加,log dump线程来处理复制请求,对主库资源消耗比较高,同时还受限于主库的网络带宽。
事务执行过程中,先把日志写到 binlog cache(Server 层的 cache),事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的binlog不能被拆开,需要保证一次性写入。因为规定一个线程只能同时有一个事务在执行,如果一个事务的binlog被拆开,在备库执行时会被当作多个事务分段执行,破坏了原子性。
MySQL 给每个线程分配了一片内存用于缓冲 binlog ,该内存叫 binlog cache,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
sync_binlog参数控制binlog刷到磁盘上的频率,权衡性能和安全。在持久化redo log和binlog两份日志时,可能会出现半成功的状态,导致主从环境的数据不一致。这是因为 redo log 影响主库的数据,binlog 影响从库的数据,所以 redo log 和 binlog 必须保持一致才能保证主从数据一致。
因此有了两阶段提交,保证分布式事务的一致性,多个逻辑操作要么全部成功,要么全部失败。
包括了两个阶段,每个阶段都由协调者(Coordinator)和参与者(Participant)共同完成:
在 MySQL 的 InnoDB 存储引擎中,开启 binlog 的情况下,MySQL 会同时维护 binlog 日志与 InnoDB 的 redo log,为了保证这两个日志的一致性,MySQL 使用了内部 XA 事务(是的,也有外部 XA 事务,跟本文不太相关,我就不介绍了),内部 XA 事务由 binlog 作为协调者,存储引擎是参与者。
补充
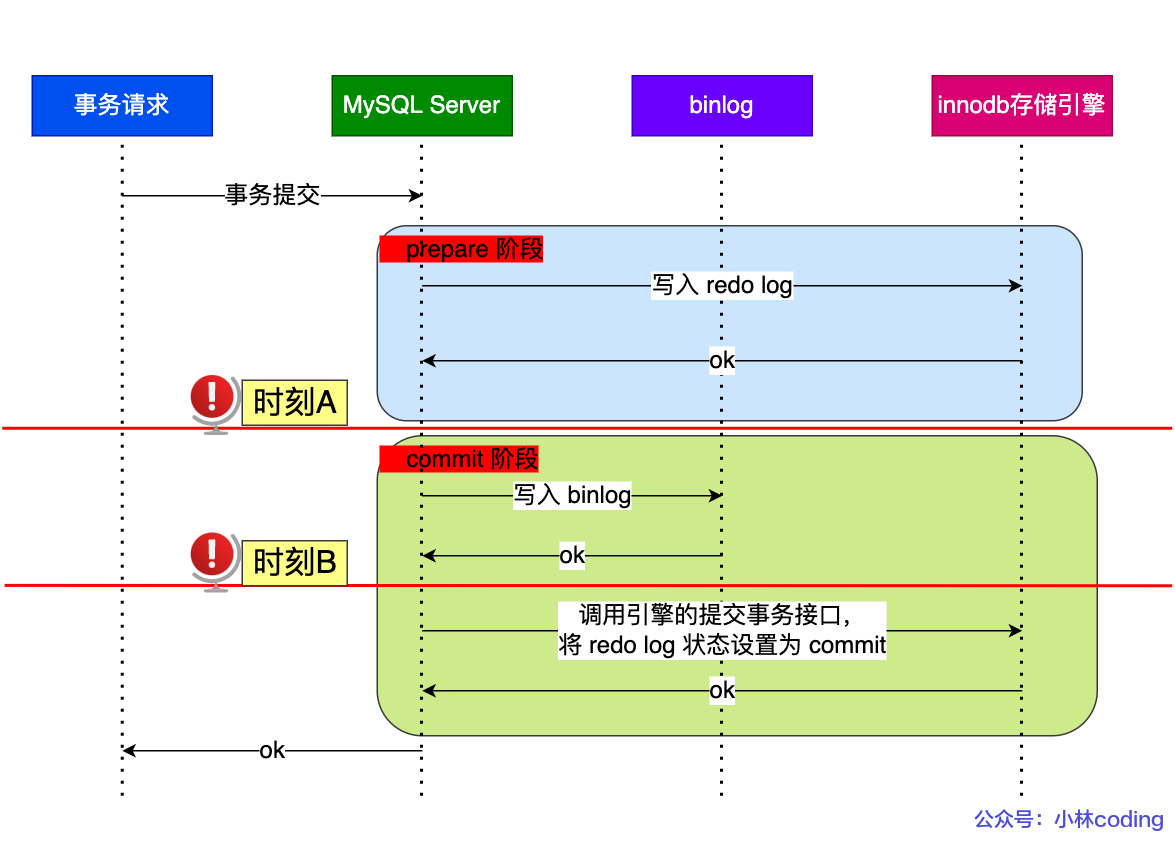
两阶段提交虽然保证了两个日志文件的数据一致性,但是性能很差,主要有两个方面的影响:
引入了组提交,当有多个事务提交的时候,会将多个 binlog 刷盘操作合并成一个,从而减少磁盘 I/O 的次数。
MySQL线上MySQL由于非外在因素(断电、硬件损坏...)导致崩溃时,辅助线上排错的日志。
主要用于记录MySQL报错信息的,涵盖了MySQL-Server的启动、停止运行的时间,以及报错的诊断信息,也包括了错误、警告和提示等多个级别的日志详情。
默认开启,无法手动关闭。
当一条SQL执行的时间超过规定的阈值后,那么这些耗时的SQL就会被记录在慢查询日志中。
查看慢查询日志定位问题,定位到产生问题的SQL后,再用explain这类工具去生成SQL的执行计划,然后根据生成的执行计划来判断为什么耗时长,是由于没走索引,还是索引失效等情况导致的。
默认关闭,慢查询日志在内存中是没有缓冲区的,也就意味着每次记录慢查询SQL,都必须触发磁盘IO来完成,因此阈值设的太小,容易使得MySQL性能下降;如果设的太大,又会导致无法检测到问题SQL,因此该值一定要设置一个合理值。
general log即查询日志,MySQL会向其中写入所有收到的查询命令,如select、show等,同时要注意:无论SQL的语法正确还是错误、也无论SQL执行成功还是失败,MySQL都会将其记录下来。
默认关闭。
从主机复制过来的bin-log数据放在哪儿呢?也就是放在relay-log日志中,中继日志的作用就跟它的名字一样,仅仅只是作为主从同步数据的“中转站”。
合理设置redo log和binlog持久化到磁盘中的时机。