type stringStruct struct{
str unsafe.Pointer
len int
}
str := "hello"
str = "Goland"
str[0] = "I" // error
str = "Hello world"
strbyte = [72 101 108 108 111 32 119 111 114 108 100]
string(strbyte) = "Hello world"
[]byte转string:
[]byte转string,在某个场景下,临时转换时,不会发生内存拷贝。
string转[]byte:
str1 := "goland"
json := `{"hello", "goland", "name": ["zhangsan"]}`
由于Go中string不能拷贝,发生拼接时会发生内存的拷贝,存在性能损耗。
常见的拼接包括了:
Q:Slice和数组的区别,Slice的扩容方式
Slice可以理解动态数组,数据扩容,是一种引用类型(值拷贝,是拷贝整个指针结构体的内容)
支持自动扩容,长度可变,申明时不需要指针大小。
type stringStruct struct{
str unsafe.Pointer // 指针变量,指向一块连续的内存空间
len int
cap int
}
可以类比到上面的string的底层,多了一个cap,支持扩容。
在初始化时,如果没有指定cap,那么cap和len相等。
在截取切片时,指向同一个底层数据,所以注意更新切片时,可能改变原切片的值。
在对切片进行复制时,复制后的切片和原来的切片指向同一块内存区域。但是数组赋值是创建新的内存区域。
这里的复制是复制了上述的结构体(重要的是其中的指针)。
追加元素不足时,slice会自动扩容
1.17之前:
1.17以后:
为了使得赋值后的数组互不干扰,应该使用copy函数。
temp := make([]int, len(cur)) // 注意len
copy(temp, cur)
为了实现一个性能优异的哈希表,需要关注两个关键点。
拉链法是哈希表最常见的实现方法,大多数的编程语言都用拉链法实现哈希表,它的实现比较开放地址法稍微复杂一些,但是平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
go语言的map其实是一个指向hmap的指针,占用8个字节。
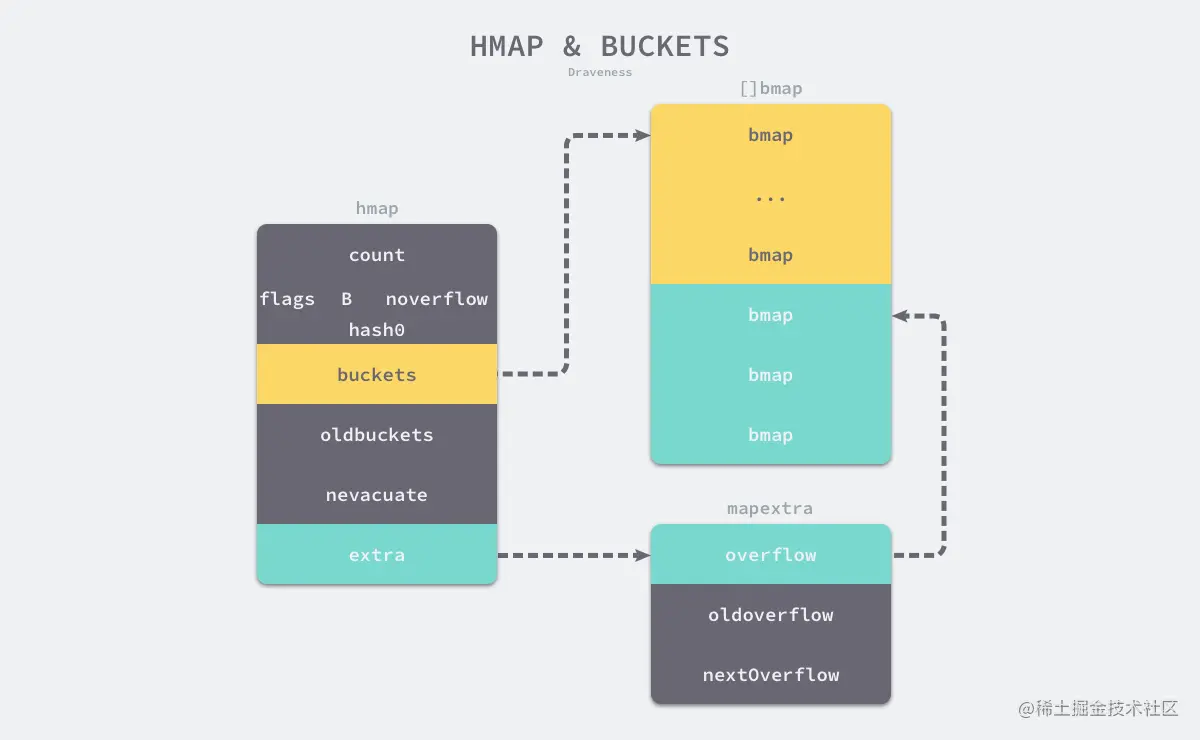
count 表示已经存储的键值对数目flags标记map的一些的状态noverflow溢出桶的数量的近似值B 表示当前哈希表持有的 buckets 数量,2^B个hash0 是哈希的种子,它能为哈希函数的结果引入随机性bucket记录桶在哪里oldbuckets 记录扩容阶段,旧桶在哪里nevacuate记录即将迁移的旧桶编号渐进式扩容,内容避免一次性扩容带来的瞬时抖动问题。
当B > 4即桶的个数大于2^4,认为发生溢出的概率比较大,会预先分配2^(B-4)个桶,并且这些桶和普通桶是连续分配的,后面作为溢出桶。
extra记录已使用的溢出桶地址,旧桶使用的溢出桶地址,下一个空闲溢出桶地址。
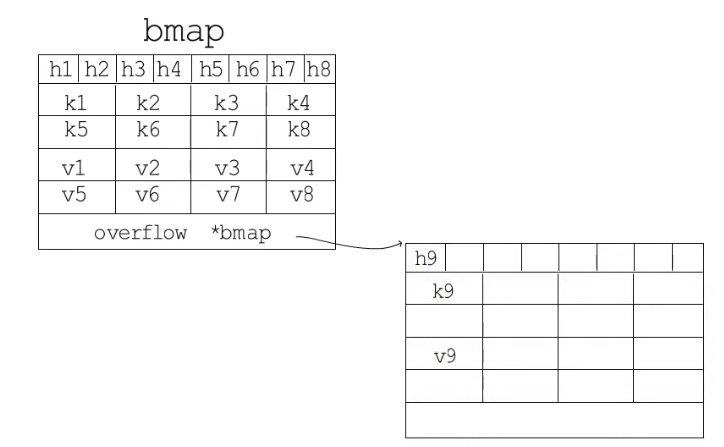
hmap中包含了多个结构为bmap的bucket数组,底层采用链表结构将bmap连接起来,处理冲突使用了优化的拉链法。
对于v:=map[key]这种方式,大体步骤是
map[key]=value形式,如果存在key更新value,如果不存在则插入新的键值对。
对map进行赋值操作时,需要初始化,否则会panic,注意var只是声明。
map是非线程安全的,当有其他线程正在读写map时,执行map的赋值会报并发读写错误。
大致流程:
随着元素不断插入,会导致map的数据量增加,hash性能变差,溢出桶增加,因此需要更多的桶和内存来保证哈希的读写性能,所以map会自动触发扩容。
以下两种情况会触发扩容:
扩容需要判断当前是否为扩容状态,避免二次扩容冲突。
经过测试6.5时数组桶快要用完的情况,存在溢出要去遍历溢出桶,所以需要扩容。
删除过多元素时,负载因子减小,再插入很多元素会创建更多的溢出桶,导致查找元素时去遍历查过的溢出桶链表,因此选择扩容,把之前的数组桶和溢出桶中元素重排。
整个过程:
迁移时机:
和访问原理差不多,会进行写检测,寻找bucket和key过程
从delete map单个key/value的原理可以看出,当我们删除一个键值对的时候,这个键值对在桶中的 内存并不会被释放,所以对与map的频繁写入和删除可能会造成内存泄漏。
每次遍历的数据顺序不同,随机一个桶以及桶内的起点槽下标,遍历时从这个桶开始,在遍历每个桶时都从这个槽开始。
why:
主要步骤,先初始化迭代器: